EagleVM: Part 1 (WIP)
Essentials of x86-64 bin2bin code virtualization
Introduction
EagleVM is a project that’s been three years in the making. It’s a compilation of research from commercial code virtualizers like VMProtect, Themida, and Enigma Protector, along with other published work. The goal is to create an open-source representation of the virtualization process.
This part of the project focuses on the processing, disassembly, virtual machine architecture, and other processes. I plan to cover more ground in future sections, discussing topics like Mixed Boolean-Arithmetic (MBA), obfuscation, and potential features that could be added to the project.
As a heads up, while EagleVM is designed to demonstrate the application and process of code virtualization, it doesn’t come with any stability guarantee. So, it’s not recommended for use on any serious code as it could introduce instabilities and undefined behavior in the output code. This is simply written for demonstration.
Please note that this blog will not provide explanations pertaining to assembly instructions and x86 architecture. For those in need of a reference or reference, the Intel IA-32 Software Developer’s Manual serves as a great resource.
Intended use is for research purposes only.
Project Structure
The solution consists of 4 primary projects listed below.
EagleVM
EagleVM is the core virtualization tool which contains all the logic for disassembling and virtualizing a target binary. It accepts an optional argument to the executable which represents the target executable to be virtualized.
EagleVM.Stub
The stub is a Dynamic Linked Library (DLL) that is used to mark code segments for virtualization in any executable application. The DLL exports 2 functions fnEagleVMBegin and fnEagleVMEnd. The desired application imports this DLL and calls the exported functions when marking the start and end of a virtualized code segment.
EagleVM searches for the calls to these functions to lift out instructions that require virtualization.
EagleVM.Sandbox
The sandbox is a test project which demonstrates the use of EagleVM.Stub.
Parsing an Input Binary
Import Marking
How It Works
When creating a binary to be virtualized, the user marks code sections using functions calls from the external DLL “EagleVMStub.dll”.
fnEagleVMBegin();
std::printf("hi :) %i", 5 + 5 * 15);
fnEagleVMEnd();However, the DLL does not provide any functionality except warn a user when they have forgotten to virtualize the program. It is simply meant for EagleVM to identify the code virtualization target.
EAGLEVMSTUB_API void __stdcall fnEagleVMBegin(void)
{
MessageBoxA(0, "Application running in unprotected mode.", "EagleVM", 0);
exit(-1);
}This technique can is often used by commercial code virtualization tools such as Themida and VMProtect. However, this comes with many downsides due to lack of structural awareness for the virtualizer tool. Smarter bin2bin frameworks will use compiler generated data such as .MAP files or .PDBs which can provide data on functions in the program and potentially avoid the complexities of parsing imports and finding calls to imports.
Loading the PE
The input binary is loaded into memory using pe_parser. pe_parser is responsible for retreiving structures defined by the Windows PE format. It has the ability of walking imports and retreiving data about sections and structures of the binary.
After the input binary is loaded, the import section of the PE is parsed and each import is walked by the pe_parser.
Then, a map of DLL imports is built so it is possible to find “EagleVMStub.dll” and its imports by using the enum_imports function.
We identify the IMAGE_IMPORT_DESCRIPTOR structure and use it to find “EagleVMStub.dll” imports.
[&stub_dll_imports](const PIMAGE_IMPORT_DESCRIPTOR import_descriptor, const PIMAGE_THUNK_DATA thunk_data, const PIMAGE_SECTION_HEADER import_section,
int index, uint8_t* data_base)
{
const uint8_t* import_section_raw = data_base + import_section->PointerToRawData;
const uint8_t* import_library = const_cast<uint8_t*>(import_section_raw +
(import_descriptor->Name - import_section->VirtualAddress));
if (std::strcmp((char*)import_library, "EagleVMStub.dll") == 0)
{
// TODO: this needs fixing because sometimes the imports will be in a different order depending on debug/release optimizations
stub_import import_type = unknown;
// get import name from index
if (thunk_data->u1.Ordinal & IMAGE_ORDINAL_FLAG)
return;
IMAGE_IMPORT_BY_NAME* import_by_name = (IMAGE_IMPORT_BY_NAME*)
(import_section_raw + (thunk_data->u1.AddressOfData - import_section->VirtualAddress));
const char* import_name = reinterpret_cast<char*>(import_by_name->Name);
if (strstr(import_name, "fnEagleVMBegin") != nullptr)
import_type = stub_import::vm_begin;
else if (strstr(import_name, "fnEagleVMEnd") != nullptr)
import_type = stub_import::vm_end;
else
import_type = stub_import::unknown;
//call rva , import type
stub_dll_imports[import_descriptor->FirstThunk + index * 8] = import_type;
}
};Next, the .text section is searched for the opcode 0xFF which is the x64 opcode for the CALL procedure.
An example of what kind byte code we are searching for can be seen below:
140001A9B: 48 89 44 24 58 mov [rsp+98h+var_40], rax
140001AA0: FF 15 62 45 01 00 call cs:__imp_?fnEagleVMBegin@@YAXXZ ; fnEagleVMBegin(void)
140001AA6: C7 44 24 60 00 00 00 00 mov [rsp+98h+var_38], 0
...
loc_140001B1A:
140001B1A: FF 15 E0 44 01 00 call cs:__imp_?fnEagleVMEnd@@YAXXZ ; fnEagleVMEnd(void)
140001B20: 83 7C 24 60 19 cmp [rsp+98h+var_38], 19hThe operands for each call are compared against the built list of stub_dll_imports. If the call matches the import rva, its identified as a call to a DLL import function specified by EagleVMStub.
Finally, all the stub imports are verified to be in order of vm_begin and vm_end. There are several issues with this which are beyond the current scope of the project to fix. For instance, compiler optimization could result in a vm_begin call being relocated after a vm_end call due to some branch optimization. In another instance, the invalid usage of the vm_begin and vm_end macro can cause the virtualizer to attempt to virtualize data in between functions which could cause undefined behavior.
Disassembling Segments
The disassembly and loading of instructions is assited by Zydis, a x86 and x86-64 dissasembler.
For each pair of IAT calls (vm_begin and vm_end) which have been verified to be in order, a pe_protection_section is created to hold data about the relative virtual addresses of the section’s instructions.
pe_protected_section protect_section = parser.offset_to_ptr(vm_iat_calls[c].first, vm_iat_calls[c + 1].first);
// by using instruction_protect_begin, we ignore the CALL to EagleVMStub
decode_vec instructions = zydis_helper::get_instructions(
protect_section.instruction_protect_begin, protect_section.get_instruction_size()
);Early Approach
The first approach was to virtualize all the instructions in a marked sections by replacing each instruction with a NOP operation. This way all the non-virtualized instructions can be hidden and so that they can be redefined elsewhere.
This was achieved by writing a JMP over the first instruction in the marked section which would jump into the .vmcode PE section where the virtualized definition for the instruction is located.
function_container container;
for(auto& instruction : instructions)
{
auto [successfully_virtualized, instructions] = vm_generator.translate_to_virtual(instruction);
if(successfully_virtualized)
{
// enter the vm if it has not been entered
if(currently_in_vm)
{
...
vm_generator.call_vm_enter(container, vmenter_return_label);
}
container.add(instructions);
}
else
{
// exit the vm if we are in it
if(currently_in_vm)
{
...
// return execution to current_rva where we failed to virtualize
vm_generator.call_vm_exit(container, jump_label);
}
}
}As a result we get assembly which looks kind of like this (in the most ideal situation):
loc_virtualized_code: ; our target protected section
nop
nop
nop
jmp eaglevmsandbox.code_section1 ; .vmcode section which contains virtualized code
nop
nop
nop
add rax, rcx ; unsupported instruction, code_section1 would return execution here
jmp eaglevmsandbox.code_section2 ; .vmcode section which contains virtualized code
nop
nop
nop
sub rax, 2 ; unsupported instruction, code_section2 would return execution hereBut a few problems come with this:
Problem 1: Overwriting
Say that we support 16 bit operand add rax, rbx. But we do not support movsx .... Well, when we try to overwrite add rax, rbx with a jmp to our .vmcode section, it will overwrite the movsx instruction which is right after it.
Target:
loc_virtualized_code: ; our target protected section
48 01 d8: add rax, rbx
48 63 44 24 32: movsx rax, dword ptr [rsp + 50]Result:
loc_virtualized_code: ; our target protected section
e9 00 00 00 00: jmp evm.code_section1 ; virtualized add rax, rbx
44 24 32 : rex.R and al,0x32 ; ????Problem 2: Control Flow
Say we fully virtualized a code section. But, somewhere else in the code (outside of our marked section), we jump to the part of the executable which had it’s code virtualized. It wont execute anything because we replaced it with NOP instructions and jumped into .vmcode.
Target:
loc_virtualized_code:
48 01 d8: add rax, rbx
some_jump:
48 01 d8: add rax, rbx
...
jmp some_jumpResult:
loc_virtualized_code:
e9 00 00 00 00: jmp evm.code_section1 ; virtualized add rax, rbx
nop
nop
nop
...
jmp some_jump ; this is doomedBetter Approach
The Idea
This approach is also simple, and provides safety from both of the issues that came from implementing the early approach.
We can analyze the control of the code section and see how conditional jumps within the code section interact with the rest of the code section. This can allow us to treat a single function target, as multiple little functions.
This kind of behavior can be seen in reverse engineering tools such as IDA. The IDA graph provides a view into the control flow of a function. Here, it can be seen that each code block ends with either a conditional jump or a normal jump. Basic blocks which use a conditional jump can potentially have 2 code paths: the relative jump located in the immediate operand or the next instruction if the condition fails.
By understanding how this control flow analsys is visualized, its possible to replicate the same form of basic block parsing. EagleVM does this through an implementation the use of the segment_disassembler which used the logic described above to create a tree of basic blocks as visualized below.
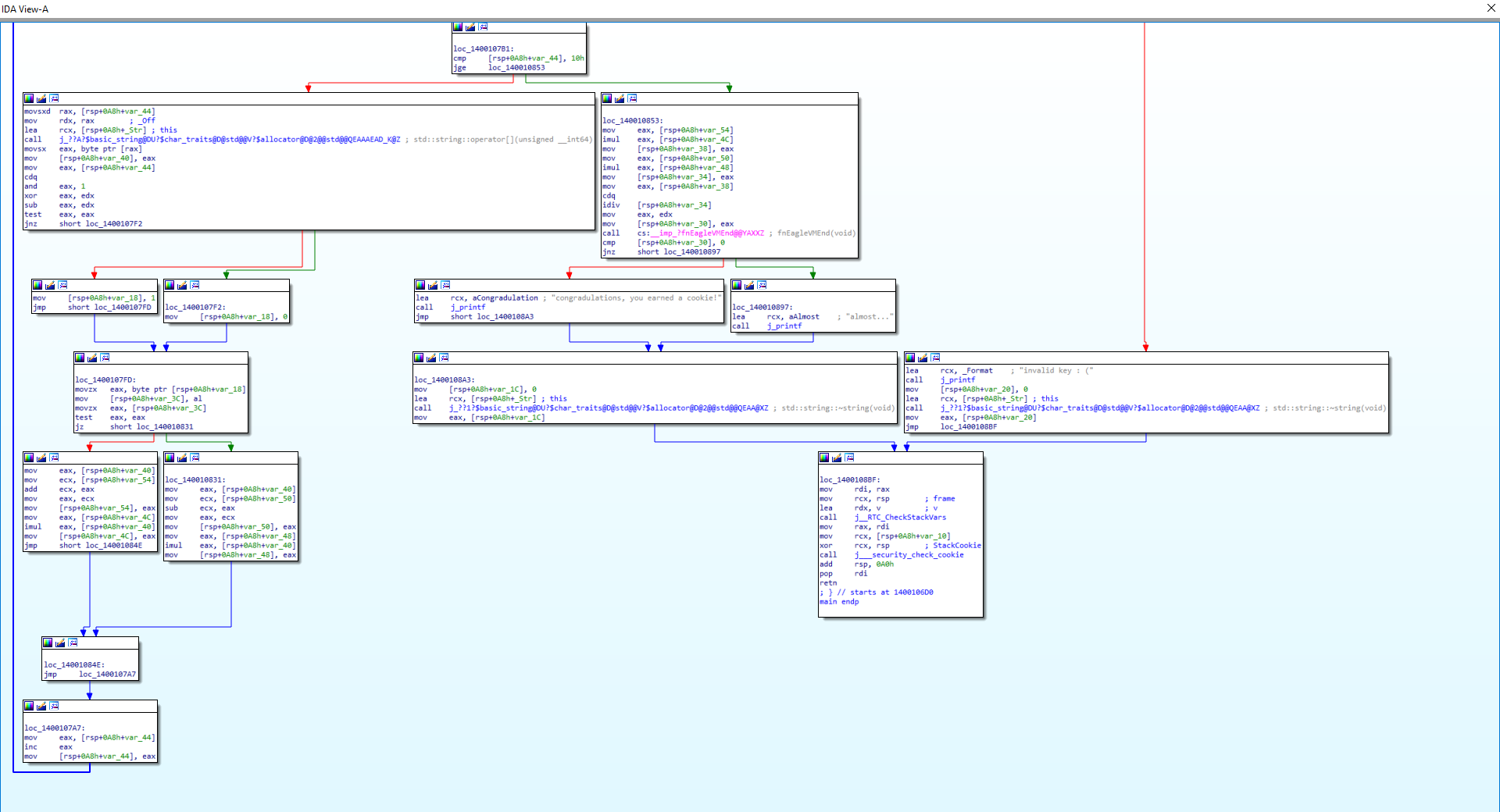
The Implementation
The class segment_disassembler will be responsible for doing all the work related to parsing the basic blocks of a segment.
segment_disassembler dasm(instructions, current_rva);
dasm.parse_blocks();During the initial pass, a basic block is created after encountering a branching instruction like JMP, JNE, or JE. Knowing this, based on whether the last instruction is JMP or a condtionally branching instruction, the value of block->end_reason will be either end_reason::block_conditional_jump or end_reason::block_jump.
uint32_t block_start_rva = rva_begin;
uint32_t current_rva = rva_begin;
decode_vec block_instructions;
for (auto& inst: function)
{
block_instructions.push_back(inst);
if (inst.instruction.meta.branch_type != ZYDIS_BRANCH_TYPE_NONE)
{
// end of our block
basic_block* block = new basic_block();
block->start_rva = block_start_rva;
block->end_rva_inc = current_rva + inst.instruction.length;
block->instructions = block_instructions;
set_block_rvas(block, current_rva);
set_end_reason(block);
blocks.push_back(block);
block_instructions.clear();
block_start_rva = block->end_rva_inc;
}
current_rva += inst.instruction.length;
}
if (!block_instructions.empty())
{
zydis_decode& inst = function.back();
basic_block* block = new basic_block();
block->start_rva = block_start_rva;
block->end_rva_inc = current_rva + inst.instruction.length;
block->instructions = block_instructions;
set_block_rvas(block, current_rva);
set_end_reason(block);
blocks.push_back(block);
}As a result of the first pass, block_instructions contains a list of instructions which end with a branching instruction. However, some branching instructions may branch into other basic blocks.
For example:
block_one:
cmp rbx, rax
block_three:
jne block_other
block_two:
inc rbx
cmp rbx, rax
jmp block_threeTo account for this behavior, the block that is being jumped into needs to be split. It is done using this algorithm which is annoying, but no need to worry about understanding it.
for (const basic_block* block: blocks)
{
if (block->target_rvas.empty())
continue;
const auto& [jump_rva, jump_type] = block->target_rvas.back();
for (basic_block* target_block: blocks)
{
// non inclusive is key because we might already be at that block
if (jump_rva > target_block->start_rva && jump_rva < target_block->end_rva_inc)
{
// we found a jump to the middle of a block
// we need to split the block
basic_block* new_block = new basic_block();
new_block->start_rva = jump_rva;
new_block->end_rva_inc = target_block->end_rva_inc;
target_block->end_rva_inc = jump_rva;
new_block->target_rvas = target_block->target_rvas;
block_jump_location location = jump_rva > rva_end || jump_rva < rva_begin ?
jump_outside_segment : jump_inside_segment;
target_block->target_rvas = {{jump_rva, location}};
target_block->end_rva_inc = jump_rva;
new_block->end_reason = target_block->end_reason;
target_block->end_reason = block_end;
// for the new_block, we copy all the instructions starting at the far_rva
uint32_t curr_rva = target_block->start_rva;
for (int i = 0; i < target_block->instructions.size();)
{
zydis_decode& inst = target_block->instructions[i];
if (curr_rva >= jump_rva)
{
// add to new block, remove from old block
new_block->instructions.push_back(inst);
target_block->instructions.erase(target_block->instructions.begin() + i);
}
else
{
i++;
}
curr_rva += inst.instruction.length;
}
new_blocks.push_back(new_block);
}
}
}
blocks.insert(blocks.end(), new_blocks.begin(), new_blocks.end());The Result
Now, the branching information of the code segment is fully determined and it’s possible to transfer code from the existing .text section into the .vmcode section where the same exact branching behavior will be replicated.
Target:
.text
loc_virt_begin:
add rax, rax
test rax, rax
add rax, rax
jnz loc_virt_other_second
loc_pseudo_one:
mov rax, 5
sub rax, 2
loc_pseudo_two:
xor rax, raxVirtualized Result:
.vmcode
loc_virt_begin:
vmenter ; enter the virtual machine
... ; vmcode
vmexit ; exit the virtual machine
test rax, rax ; unsupported vm instruction! exit!
vmenter ; reenter the virtual machine
... ; vmcode
vmexit ; ALWAYS exit before jmp and before end of block
jnz loc_virt_other_second
loc_virt_other_first:
vmenter ; reenter the virtual machine
... ; vmcode
vmexit ; we exit the vm ALWAYS at the end of a block
loc_virt_other_second:
vmenter ; reenter the virtual machine
... ; vmcode
vmexit ; exit
jmp orig_func ; return execution back to .textThis way, we have replicated the control flow of the target, but we can add and remove as many instructions as we want. We are not limited by the size of the .text section or the location of where these jumps go since we accurately replicated the control flow!
By analyzing the code generated by the compiler, its easier to create safe and executable virtual machine code which maintains the integrity of the original instructions.
Virtual Machine Architecture
x86-64 and VM Context
Most of my research for this project came from researching VMProtect 2.0 and 3.0. As a result, a lot of the features of VMProtect’s VM architecture are present in this project. However, the project has a lot of its own DNA in terms of the virtual call stack and the usage of non convential stack manipulation which I hope to expand on in the future.
x86-64 Context
The existing x86-64 register context is stored on the stack. Each register is chosen and stored in a predefined order which is shuffled using a random number generator. Its important to note in the current implementation, RFLAGS is always stored first on the stack due to current automation of how VMENTER and VMEXIT is generated.
For example:
0x0: RFLAGS ; always first
0x8: RAX ; R0
0X10: RBX ; R1
0x18: RCX ; R2
...
0x88: R15 ; R15Every register R0-R15 is stored here. The VM does not support operands related to XMM registers. Therefore, instructions involving XMM registers are not managed, and the registers themselves are not retained.
VM Context
Registers
Since the x86-64 context is stored on the stack, registers R0-R15 are free to use for the VM context. Currently, 7 registers are required for the virtual machine to execute but could ultimately be minimized.
- VIP: Responsible for doing RIP relative calculations
- VSP: Responsible for emulating the functionality of RSP
- VREGS: Contains a pointer to the top of the stack after all registers have been pushed
- VTEMP: Temporary register used for calculations
- VTEMP2: Temporary register used for calculations
- VCS: A pointer to the virtual machine call stack
- VCSRET: Responsible for holding the RVA used in VIP calculations
Call Stack
The native stack is utilized by the virtual machine to maintain a virtual call stack called VCS. In some VM designs, if a VM handler requires the functionality of a virtual POP, it will inline the virtual instruction inside of the VM handler. However, in EagleVM’s virtual machine design, a virtual call stack is created after VREGS which contains the addresses to which the handler needs to return to.
For instance, if we were to be executing code in VMADD, it would require the functionality of VMPOP to get the value which we would like to add from the top of the stack.
VMADD:
VMPOP ; pop 2nd operand
add [VSP], VTEMP ; add to 1st operandStack at VMPOP:
0x88: R15 ; final register on VREGS
0x90: 0x1450 ; RVA of VMADD return <- VCS at VMPOPOnce VMPOP finishes execution, it will pop from the virtual call stack, and preform a RIP relative jump to return execution back to VMADD
Stack at VMADD:
0x88: R15 ; final register on VREGS <- VCS at VMADD
0x90: ...Context Overview
It may be difficult to imagine what the combination of the x86-64 context and VM context may actually look like on the stack, so let me put it into perspective.
Once VMENTER concludes, the stack should look something like this:
0x0: <- VSP old RSP some stack data
... Stack allocated by VM
...
0x100 RFLAGS <- RSP
0x108 R0
0x110 R1
0x118 R2
... All other registers
0x188 R15 <- VREGS, VCSHandler Abstraction
VM Register Macros
The examples below demonstrate how EagleVM generates VM and x86 instruction handlers. Initially, the code may appear perplexing as it utilizes registers like VSP or VREGS. However, in the code, macros such as VREGS/VTEMP/etc invoke a function that informs the virtual machine generator about the actual x86 mapping for the register. The value I_VREGS passed into the function represents a unique index for an array containing the shuffled order of R0-R15.
#define I_VIP 0
#define I_VSP 1
#define I_VREGS 2
#define I_VTEMP 3
#define I_VTEMP2 4
#define I_VCALLSTACK 5
#define I_VCSRET 6
...
#define VSP rm_->get_reg(I_VSP)
#define VREGS rm_->get_reg(I_VREGS)The call could potentially yield a value like this:
rm_->get_reg(I_VREGS) -> GR_RBXFor a deeper understanding on how this shuffle occurs, the definition of init_reg_order is needed. The register order is continuously shuffled until the indexes of our virtual registers do not colide with registers that will alter the VMs execution (RIP and RSP). This allows safe access of registers through get_reg.
void vm_register_manager::init_reg_order()
{
for(int i = ZYDIS_REGISTER_RAX; i <= ZYDIS_REGISTER_R15; i++)
reg_stack_order_[i - ZYDIS_REGISTER_RAX] = static_cast<zydis_register>(i);
bool success_shuffle = false;
std::array<zydis_register, 16> access_order = reg_stack_order_;
while(!success_shuffle)
{
std::ranges::shuffle(access_order, ran_device::get().gen);
success_shuffle = true;
for(int i = 0; i < NUM_OF_VREGS; i++)
{
const zydis_register target = access_order[i];
// these are registers we do not want to be using as VM registers
if(target == ZYDIS_REGISTER_RIP || target == ZYDIS_REGISTER_RSP)
{
success_shuffle = false;
break;
}
}
}
reg_vm_order_ = access_order;
}
zydis_register vm_register_manager::get_reg(const uint8_t target) const
{
// target would be something like VIP, VSP, VTEMP, etc
return reg_vm_order_[target];
}Get Bit Version
Some handlers require a specific bit size of the VTEMP register to match the target handler. The target VTEMP such as VTEMP32 or VTEMP16 will be retreived through get_bit_version such as this:
zydis_register target_temp = zydis_helper::get_bit_version(VTEMP, reg_size); // reg_size = bit64, bit32, bit16, ...Operand Macros
// REGISTER
#define ZREG(x) ...
// UNSIGNED IMMEDIATE
#define ZIMMU(x) ...
// SIGNED IMMEDIATE
#define ZIMMS(x) ...
// Z BYTES MEM[REG(X) + Y]
#define ZMEMBD(x, y, z) ...
// A BYTES MEM[REG(X) + (REG(Y) * Z)]
#define ZMEMBI(x, y, z, a) ...Virtual Machine Handlers
VMENTER
VMENTER is arguably the most important virtual machine handler in the project. Its responsible for allocating stack space for the virtual machine, saving all relevant registers on the stack, and setting up virtual machine registers. Before the routine is called, the RVA of the first basic block in the virtualized function is pushed using push rva. This address is later accessed at the end of VMENTER to return execution.
Generator:
void vm_enter_handler::construct_single(function_container& container, reg_size size, uint8_t operands)
{
container.add(zydis_helper::enc(ZYDIS_MNEMONIC_LEA, ZREG(GR_RSP), ZMEMBD(GR_RSP, -(8 * vm_overhead), 8)));
container.add(zydis_helper::create_encode_request(ZYDIS_MNEMONIC_PUSHFQ));
std::ranges::for_each(PUSHORDER,
[&container](short reg)
{
container.add(zydis_helper::enc(ZYDIS_MNEMONIC_PUSH, ZREG(reg)));
});
container.add({
zydis_helper::enc(ZYDIS_MNEMONIC_MOV, ZREG(VSP), ZREG(GR_RSP)),
zydis_helper::enc(ZYDIS_MNEMONIC_MOV, ZREG(VREGS), ZREG(VSP)),
zydis_helper::enc(ZYDIS_MNEMONIC_MOV, ZREG(VCS), ZREG(VSP)),
zydis_helper::enc(ZYDIS_MNEMONIC_LEA, ZREG(GR_RSP), ZMEMBD(VREGS, 8 * (vm_stack_regs), 8)),
zydis_helper::enc(ZYDIS_MNEMONIC_LEA, ZREG(VTEMP), ZMEMBD(VSP, 8 * (vm_stack_regs + vm_overhead), 8)),
zydis_helper::enc(ZYDIS_MNEMONIC_MOV, ZREG(VTEMP), ZMEMBD(VTEMP, 0, 8)),
zydis_helper::enc(ZYDIS_MNEMONIC_LEA, ZREG(VCS), ZMEMBD(VCS, -8, 8)),
zydis_helper::enc(ZYDIS_MNEMONIC_MOV, ZMEMBD(VCS, 0, 8), ZREG(VTEMP)),
});
code_label* rel_label = code_label::create();
container.add(rel_label, RECOMPILE(zydis_helper::enc(ZYDIS_MNEMONIC_LEA, ZREG(VBASE), ZMEMBD(IP_RIP, -rel_label->get(), 8))));
container.add({
zydis_helper::enc(ZYDIS_MNEMONIC_LEA, ZREG(VTEMP), ZMEMBD(VSP, 8 * (vm_stack_regs + vm_overhead + 1), 8)),
zydis_helper::enc(ZYDIS_MNEMONIC_MOV, ZREG(VSP), ZREG(VTEMP)),
});
create_vm_return(container);
}Assembly Pseudocode:
pushfq ; store RFLAGS
push r0-r15 ; store R0-R15
mov VSP, rsp ; begin virtualization by setting VSP to rsp
mov VREGS, VSP ; set VREGS to currently pushed stack items
mov VCS, VSP ; set VCALLSTACK to current stack top
lea rsp, [rsp + stack_regs + 1] ; this allows us to move the stack pointer in such a way that pushfq overwrite rflags on the stack
lea VTEMP, [VSP + (8 * (stack_regs + vm_overhead))]
; load the address of where return address is located
mov VTEMP, [VTEMP] ; load actual value into VTEMP
lea VCS, [VCS - 8] ; allocate space to place return address
mov [VCS], VTEMP ; put return address onto call stack
lea VBASE, [image_base] ; rip relative instruction to retreive image base
lea VTEMP, [VSP + (8 * (stack_regs + vm_overhead) + 1)]
; load the address of the original rsp (+1 because we pushed an rva)
mov VSP, VTEMPThe routine is called like this:
void vm_generator::call_vm_enter(function_container& container, code_label* vmenter_target)
{
const vm_handler_entry* vmenter = hg_->v_handlers[MNEMONIC_VM_ENTER];
const auto vmenter_address = vmenter->get_vm_handler_va(bit64);
container.add(RECOMPILE(zydis_helper::enc(ZYDIS_MNEMONIC_PUSH, ZLABEL(vmenter_target))));
code_label* rel_label = code_label::create("call_vm_enter_rel");
container.add(rel_label, RECOMPILE(zydis_helper::enc(ZYDIS_MNEMONIC_JMP, ZJMP(vmenter_address, rel_label))));
}Note: While the stack is modified to be able to perform this push, VMENTER later offsets the change in the stack pointer to allow the program to execute as it normally should.
VMEXIT
VMEXIT is responsible for exiting the virtual machine state and restoring all original registers to the values of VREGS stored on the stack. Finally, it returns execution to the RVA that is stored in VTEMP. The return address for this routine is located in the virtual register VCSRET.
void vm_exit_handler::construct_single(function_container& container, reg_size size, uint8_t operands)
{
// we need to place the target RSP after all the pops
// lea VTEMP, [VREGS + vm_stack_regs]
// mov [VTEMP], VSP
container.add({
zydis_helper::enc(ZYDIS_MNEMONIC_LEA, ZREG(VTEMP), ZMEMBD(VREGS, 8 * vm_stack_regs, 8)),
zydis_helper::enc(ZYDIS_MNEMONIC_MOV, ZMEMBD(VTEMP, 0, 8), ZREG(VSP))
});
// we also need to setup an RIP to return to main program execution
// we will place that after the RSP
code_label* rel_label = code_label::create();
container.add(rel_label, RECOMPILE(zydis_helper::enc(ZYDIS_MNEMONIC_LEA, ZREG(VIP), ZMEMBD(IP_RIP, -rel_label->get(), 8))));
container.add(zydis_helper::enc(ZYDIS_MNEMONIC_LEA, ZREG(VIP), ZMEMBI(VIP, VCSRET, 1, 8)));
container.add(zydis_helper::enc(ZYDIS_MNEMONIC_MOV, ZMEMBD(VSP, -8, 8), ZREG(VIP)));
// mov rsp, VREGS
container.add(zydis_helper::enc(ZYDIS_MNEMONIC_MOV, ZREG(GR_RSP), ZREG(VREGS)));
//pop r0-r15 to stack
std::for_each(PUSHORDER.rbegin(), PUSHORDER.rend(),
[&container](short reg)
{
if(reg == ZYDIS_REGISTER_RSP || reg == ZYDIS_REGISTER_RIP)
{
container.add(zydis_helper::enc(ZYDIS_MNEMONIC_LEA, ZREG(GR_RSP), ZMEMBD(GR_RSP, 8, 8)));
return;
}
container.add(zydis_helper::enc(ZYDIS_MNEMONIC_POP, ZREG(reg)));
});
//popfq
container.add(zydis_helper::enc(ZYDIS_MNEMONIC_POPFQ));
// the rsp that we setup earlier before popping all the regs
container.add(zydis_helper::enc(ZYDIS_MNEMONIC_POP, ZREG(GR_RSP)));
container.add(zydis_helper::enc(ZYDIS_MNEMONIC_JMP, ZMEMBD(GR_RSP, -8, 8)));
}Assembly Pseudocode:
lea VTEMP, [VREGS + vm_stack_regs] ; load address after VREGS
mov [VTEMP], VSP ; store the destination RSP as the last stack pop
lea VIP, [140000000] ; load image base
lea VIP, [VIP + VCSRET] ; add return address rva
mov [VSP - 8], VIP ; store return address above RSP
mov rsp, VREGS ; setup RSP to pop all VREGS
pop r15-r0 ; load stack values into registers
popfq ; restore RFLAGS
pop rsp ; set RSP to target value
jmp [rsp - 8] ; jump to return RVA
This routine requires quite a bit of trickery as restoring the RSP and RIP changes how the program executes. Popping the RSP will prevent us from popping directly from the stack in the desired order, but popping RIP will no longer allow for VMEXIT instructions to execute. Ultimately, this is solved by placing a target RSP at the bottom of the vm stack register store and storing a return address 1 push before this location.
The routine is called like this:
void vm_generator::call_vm_exit(function_container& container, code_label* vmexit_target)
{
const vm_handler_entry* vmexit = hg_->v_handlers[MNEMONIC_VM_EXIT];
const auto vmexit_address = vmexit->get_vm_handler_va(bit64);
// mov VCSRET, ZLABEL(target)
container.add(RECOMPILE(zydis_helper::enc(ZYDIS_MNEMONIC_MOV, ZREG(VCSRET), ZLABEL(vmexit_target))));
// lea VIP, [VBASE + vmexit_address]
// jmp VIP
container.add(RECOMPILE(zydis_helper::enc(ZYDIS_MNEMONIC_LEA, ZREG(VIP), ZMEMBD(VBASE, vmexit_address->get(), 8))));
container.add(zydis_helper::enc(ZYDIS_MNEMONIC_JMP, ZREG(VIP)));
}Note: Since we do not intend to return execution after it is called, the virtual call stack is not utalized for this call.
VMLOAD
The VMLOAD routine supports 64, 32, 16, and 8 bit operand widths. This routine accepts a parameter in VTEMP which represents the offset to the register that needs to be loaded on to the stack. The code calling this vm handler needs to calculate the stack displacement from the predetermined stack displacement to where a target register is stored. Depending on which register size this handler is called for, it will read a different amount of memory coresponding to that register size.
void vm_load_handler::construct_single(function_container& container, reg_size reg_size, uint8_t operands)
{
uint64_t size = reg_size;
dynamic_instructions_vec handle_instructions;
const inst_handler_entry* push_handler = hg_->inst_handlers[ZYDIS_MNEMONIC_PUSH];
auto target_temp = zydis_helper::get_bit_version(VTEMP, reg_size);
container.add(zydis_helper::enc(ZYDIS_MNEMONIC_MOV, ZREG(target_temp), ZMEMBI(VREGS, VTEMP, 1, reg_size)));
call_vm_handler(container, push_handler->get_handler_va(reg_size, 1));
create_vm_return(container);
}Assembly Pseudocode:
mov VTEMP, [VREGS + VTEMP]
call PUSH
retAn example of how this vm handler is called can be seen in the base instruction handler which will be explored in a later part of the blog. When a base register of a memory operand such as [RBX + 0x50] needs to be loaded onto the stack, the displacement is calculated and the handler is called like this:
const vm_handler_entry* lreg_handler = hg_->v_handlers[MNEMONIC_VM_LOAD_REG];
const auto lreg_address = lreg_handler->get_vm_handler_va(bit64);
const auto [base_displacement, base_size] = rm_->get_stack_displacement(op_mem.base);
container.add(zydis_helper::enc(ZYDIS_MNEMONIC_MOV, ZREG(VTEMP), ZIMMU(base_displacement)));
call_vm_handler(container, lreg_address);VM_POP_RFLAGS
The VM_POP_RFLAGS routine a 64 bit only instruction. It is responsible for loading the RFLAGS stored on top of the stack into the designated RFLAGS VREGS location.
void vm_pop_rflags_handler::construct_single(function_container& container, reg_size size, uint8_t operands)
{
container.add({
zydis_helper::enc(ZYDIS_MNEMONIC_MOV, ZREG(VTEMP), ZREG(GR_RSP)),
zydis_helper::enc(ZYDIS_MNEMONIC_MOV, ZREG(GR_RSP), ZREG(VSP)),
zydis_helper::enc(ZYDIS_MNEMONIC_POPFQ),
zydis_helper::enc(ZYDIS_MNEMONIC_MOV, ZREG(VSP), ZREG(GR_RSP)),
zydis_helper::enc(ZYDIS_MNEMONIC_MOV, ZREG(GR_RSP), ZREG(VTEMP)),
zydis_helper::enc(ZYDIS_MNEMONIC_PUSHFQ),
zydis_helper::enc(ZYDIS_MNEMONIC_LEA, ZREG(GR_RSP), ZMEMBD(GR_RSP, 8, 8))
});
create_vm_return(container);
}Assembly Pseudocode:
mov VTEMP, RSP ; RSP stores the stack address prior to where RFLAGS is stored
mov RSP, VSP ; RSP is moved to the virtual stack where the new RFLAGS are stored
popfq ; RFLAGS is popped from the virtual stack
mov VSP, RSP ; VSP is restored to the address after the pop
mov RSP, VTEMP ; RSP is restored to the location prior to where RFLAGS is stored
pushfq ; RFLAGS located in VREGS is overwritten by the new RFLAGS
lea RSP, [RSP + 8] ; RSP is restored prior to where RFLAGS is storedIn short, RFLAGS is popped from the stack, old RFLAGS in VREGS is overwritten, and RSP is restored so that RFLAGS can be overwritten again in a future call to VM_POP_RFLAGS. Unfortunately, manipulating RFLAGS is difficult because there is no direct way to write the register. As a result, some stack manipulation tricks are required to get PUSHFQ/POPFQ to work as intended.
VM_PUSH_RFLAGS
void vm_push_rflags_handler::construct_single(function_container& container, reg_size size, uint8_t operands)
{
container.add({
zydis_helper::enc(ZYDIS_MNEMONIC_MOV, ZREG(VTEMP), ZREG(GR_RSP)),
zydis_helper::enc(ZYDIS_MNEMONIC_MOV, ZREG(GR_RSP), ZREG(VSP)),
zydis_helper::enc(ZYDIS_MNEMONIC_PUSHFQ),
zydis_helper::enc(ZYDIS_MNEMONIC_MOV, ZREG(VSP), ZREG(GR_RSP)),
zydis_helper::enc(ZYDIS_MNEMONIC_MOV, ZREG(GR_RSP), ZREG(VTEMP)),
});
create_vm_return(container);
}VM_TRASH_RFLAGS
void vm_trash_rflags_handler::construct_single(function_container& container, reg_size size, uint8_t operands)
{
const inst_handler_entry* pop_handler = hg_->inst_handlers[ZYDIS_MNEMONIC_POP];
call_vm_handler(container, pop_handler->get_handler_va(bit64, 1));
container.add({
zydis_helper::enc(ZYDIS_MNEMONIC_LEA, ZREG(GR_RSP), ZMEMBD(GR_RSP, -8, 8)),
zydis_helper::enc(ZYDIS_MNEMONIC_POPFQ),
});
create_vm_return(container);
}VMSTORE
void vm_store_handler::construct_single(function_container& container, reg_size reg_size, uint8_t operands)
{
const inst_handler_entry* pop_handler = hg_->inst_handlers[ZYDIS_MNEMONIC_POP];
container.add(zydis_helper::enc(ZYDIS_MNEMONIC_LEA, ZREG(VTEMP2), ZMEMBI(VREGS, VTEMP, 1, 8)));
call_vm_handler(container, pop_handler->get_handler_va(reg_size, 1));
container.add(zydis_helper::enc(ZYDIS_MNEMONIC_MOV, ZMEMBD(VTEMP2, 0, 8), ZREG(VTEMP)));
create_vm_return(container);
}x86-64 Instruction Handlers
For the most part, the instruction handlers are not interesting and are pretty repetitive so I will not be explaining each one. But some special cases require overloading base instruction virtualization routines. And in others, extra logic is required after the execution of the VM handler.
ADD / SUB
MOVSX
PUSH / POP
Extra
Virtualizing Instructions
Project Flaws
Special Thanks
Ending Notes
I intend to work privately on this project while also addressing minor bugs in the public version. I welcome any contributions. If you’re interested in code virtualization, feel free to clone the project and explore. The code is sufficiently abstracted to facilitate the integration of new features. For those seeking a challenge, you could fix project defects, implement VM handlers, add your own obfuscation passes, or pursue any other changes that interests you.
If you would like to ask questions about the project, feel free to create a GitHub issue or reach out to me on Discord at @writecr3
Please note that the project is licensed under GPL-3.0.